This article aims to quickly and concisely understand what Druid is and "how to use it".
Let's look at these questions:
- Do you have a huge amount of event data?
- Do you need to provide low-latency queries in addition to the data?
If your answer to any question is a definite YES, then Druid is something you must pay attention to. Druid is a wonderful open-source software in the field of big data and data warehouses from the Apache Software Foundation. It is written in Java and is a column-oriented distributed data store (or also called a columnar DB).
Can you trust Druid? Yes! Alibaba, Airbnb, Cisco, eBay, and many other well-known companies use Druid, and it actually started with the marketing company Metamarkets, then was supported by a large open-source community and began its distribution under Apache licenses.
Although it is not a relational database, it has many similarities with a relational database, which helps us understand Druid very quickly.
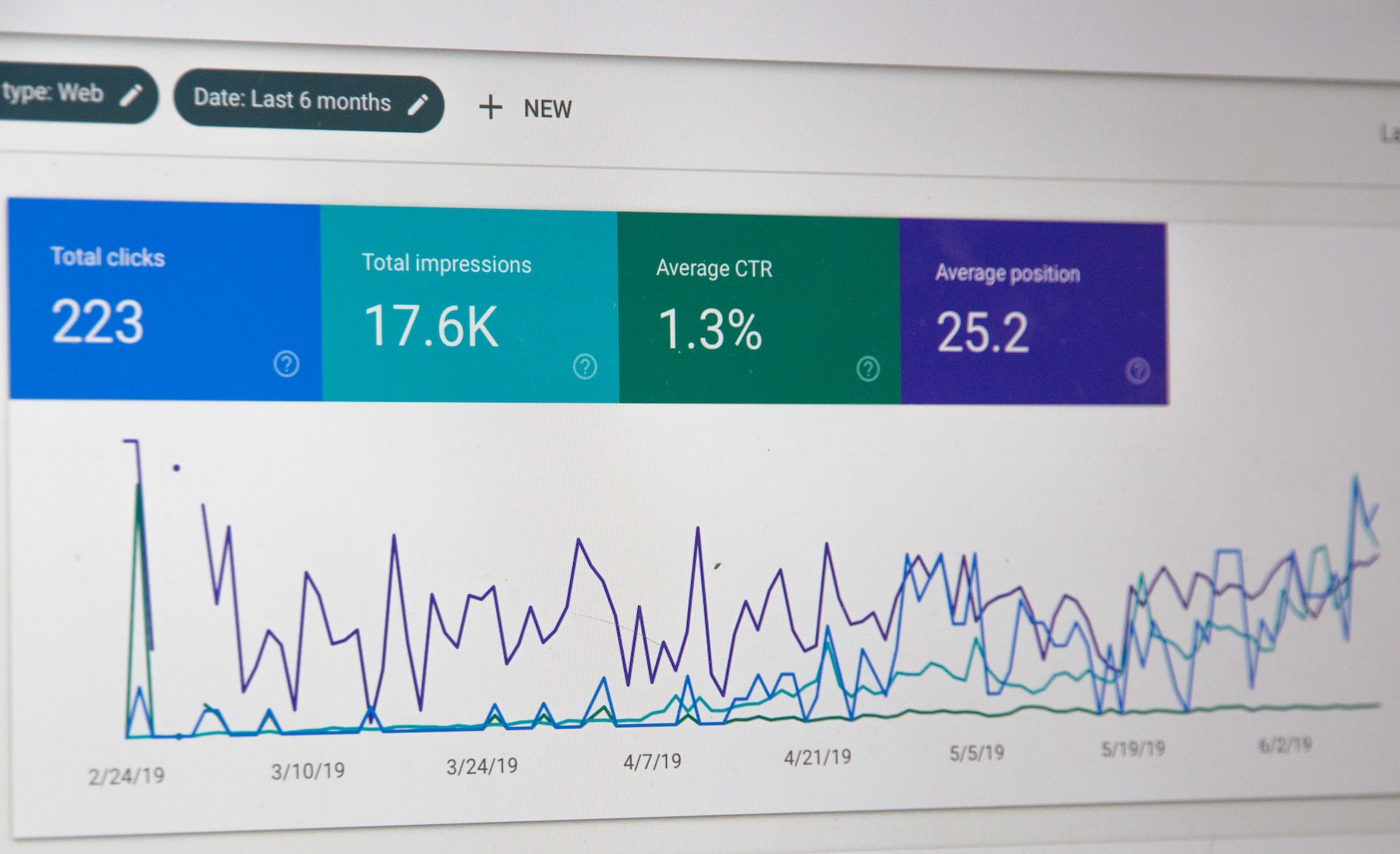
How much data can Druid handle? I can answer this question by quoting a statement from the Netflix blog: “Netflix is currently loading over 2 million events per second and querying over 1.5 trillion rows to get detailed information about Druid. Below are some of the main advantages of Druid:
- Fast real-time reporting on a large array of data;
- Long-term storage using HDFS;
- High availability;
- Extremely efficient querying of large data sets;
- Aggregation and indexing;
- High-level data compression;
- Hive integration and more;
- Can out-of-the-box pull data from Kafka and others;
- Cool API and understandable query language (even SQL-like);
- Supports various data loading formats (from CSV and JSON to Avro);
- Good and complete documentation;
- Open source with all its advantages.
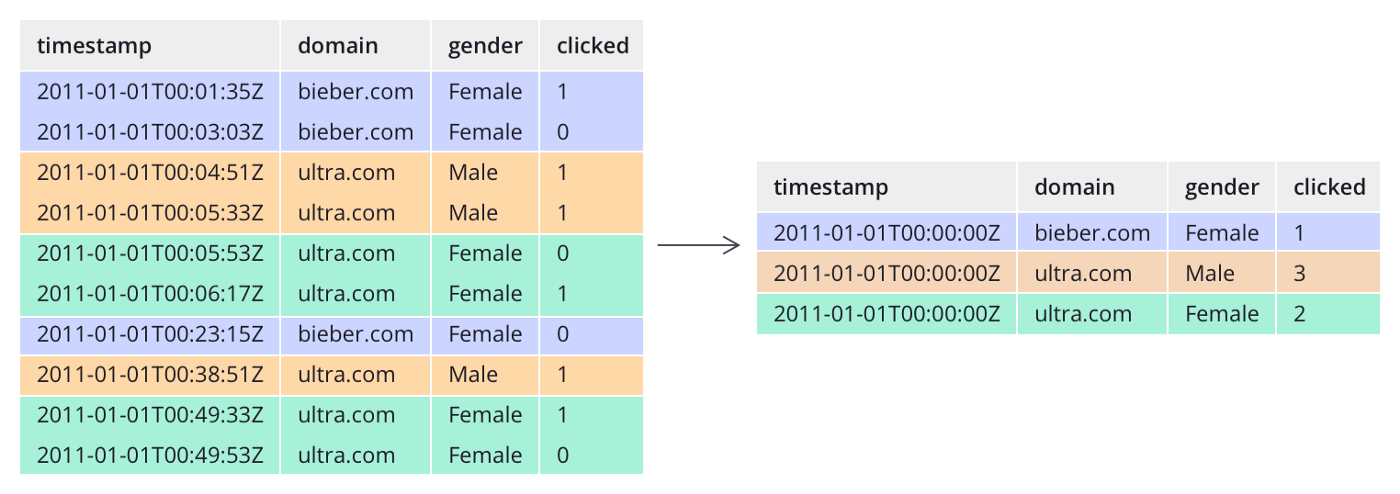
Unlike many traditional systems, Druid can additionally pre-aggregate data as it arrives. This stage of pre-aggregation is known as rollup and can lead to significant memory savings.
Example of data aggregation by Druid:
What next? Next is practice. Familiarize yourself with the full description of Druid on the official website and start practicing.
Good luck! ;)
Makhno Mykhailo.