Эта статья направлена на то, чтобы быстро и кратко понять, что такое Druid и "с чем его едят".
Давайте рассмотрим такие вопросы:
- У вас есть огромное количество данных о событиях?
- Вам нужно предоставлять запросы с низкой задержкой в дополнение к данным?
Если ваш ответ на любой вопрос - утвердительное ДА, то Druid - это то, на что вам обязательно стоит обратить внимание. Druid - это замечательное программное обеспечение с открытым исходным кодом в области больших данных и хранилищ данных от Apache Software Foundation. Он написан на Java и представляет собой колоночное распределённое хранилище данных (или ещё говорят, что это колонковая БД).
Можете ли вы доверять Druid? Да! Alibaba, Airbnb, Cisco, eBay и многие другие известные компании используют Druid, и изначально он начинался с маркетинговой компании Metamarkets, затем был поддержан большим opensource-сообществом и начал своё распространение под лицензиями Apache.
Хотя это не реляционная база данных, у него есть много сходств с реляционной базой данных, что помогает нам очень быстро понять Druid.
Сколько данных может обрабатывать Druid? Я могу ответить на этот вопрос, процитировав заявление с блога Netflix: «Netflix в настоящее время загружает более 2 миллионов событий в секунду и запрашивает более 1,5 триллионов строк, чтобы получить детальную информацию о Druid. Ниже приведены некоторые основные преимущества Druid:
- Быстрое получение отчетов в реальном времени о большом массиве данных;
- Долгосрочное хранение с использованием HDFS;
- Высокая доступность;
- Чрезвычайно эффективные запросы к большим наборам данных;
- Агрегация и индексация;
- Высокоуровневое сжатие данных;
- Интеграция с Hive и другими;
- Может из коробки извлекать данные из Kafka и других;
- Крутой API и понятный язык запросов (даже похож на SQL);
- Поддерживает различные форматы загрузки данных (от CSV и JSON до Avro);
- Хорошая и полная документация;
- Opensource со всеми его преимуществами.
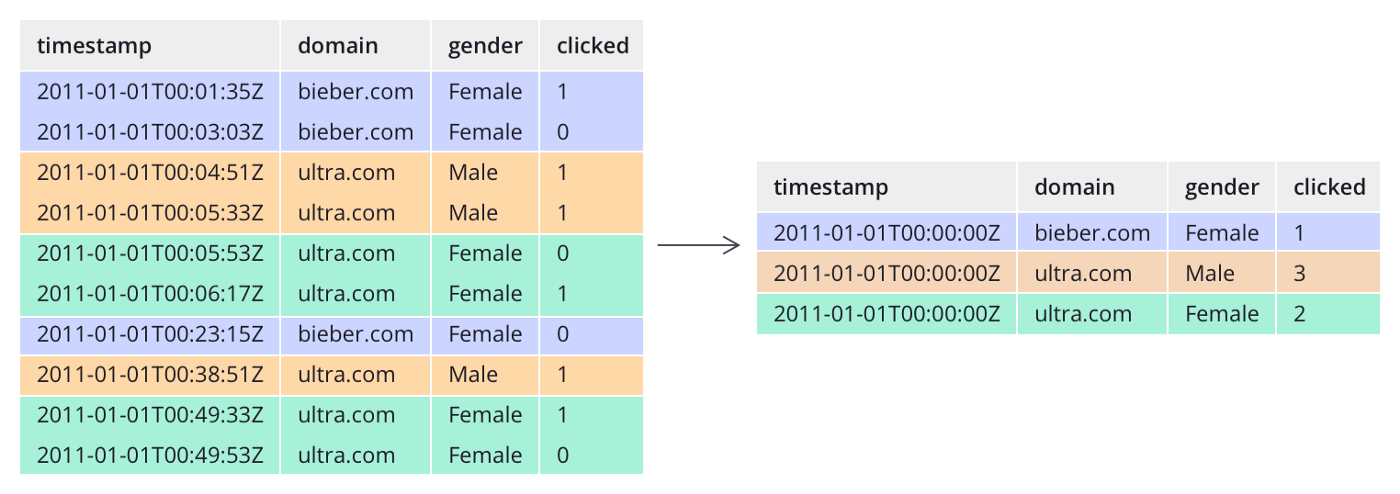
В отличие от многих традиционных систем, Druid может дополнительно предварительно агрегировать данные по мере их поступления. Этот этап предварительной агрегации известен как свёртывание и может привести к значительной экономии памяти.
Пример агрегации данных Druid-ом:
Что дальше? Далее дело за практикой. Ознакомьтесь с полным описанием Druid на официальном сайте и начинайте практиковаться.
Удачи! ;)
Махно Михаил.