Ця стаття направленя на те щоб швидко та коротко зрозуміти що ж таке Druid та "з чим його вживати".
Давайте подивимось на такі питання:
- У вас є величезна кількість даних про події?
- Вам потрібно надавати запити з низькою затримкою на додаток до даних?
Якщо ваша відповідь на будь-яке запитання - ствердне ТАК, то Druid - те, на що Ви обов'язково маєте звернути свою увагу. Druid - це чудове програмне забезпечення з відкритим кодом у галузі великих даних та сховищ даних від Apache Software Foundation. Він написаний на Java та є орієнтованим на стовпці розподіленим сховищем даних (або ще кажуть, що це колонкова БД).
Чи можете Ви довіряти Druid? Так! Alibaba, Airbnb, Cisco, eBay та багато інших відомих компаній використовують Druid, а взагалі він починався з маркетингової компанії Metamarkets, а далі була підтримана великою opensource-спільнотою та почала своє розповсюдження під ліцензіями Apache.
Хоча це не реляційна база даних, вона має багато схожості з реляційною базою даних, що допомагає нам дуже швидко зрозуміти Druid.
Скільки даних може обробляти Druid? Я можу відповісти на це запитання, процитувавши заяву з блогу Netflix: «Netflix наразі завантажує понад 2 мільйони подій на секунду та запитує понад 1,5 трильйона рядків, щоб отримати детальну інформацію про Druid. Нижче наведено деякі основні переваги Druid:
- Швидке отримання звітів у реальному часі про великий масив даних;
- Довгострокове зберігання з використанням HDFS;
- Висока доступність;
- Надзвичайно ефективне надсилання запитів до великих наборів даних;
- Агрегація та індексація;
- Високорівневе стиснення даних;
- Інтеграція Hive та ін;
- Може з коробки забирати дані з Kafka та ін;
- Круте API та зрозуміла мова запитів (навіть SQL-подібна);
- Підтримує різні формати завантаження даних (від CSV та JSON до Avro);
- Хороша та повна документація;
- Opensource з усіма його перевагами.
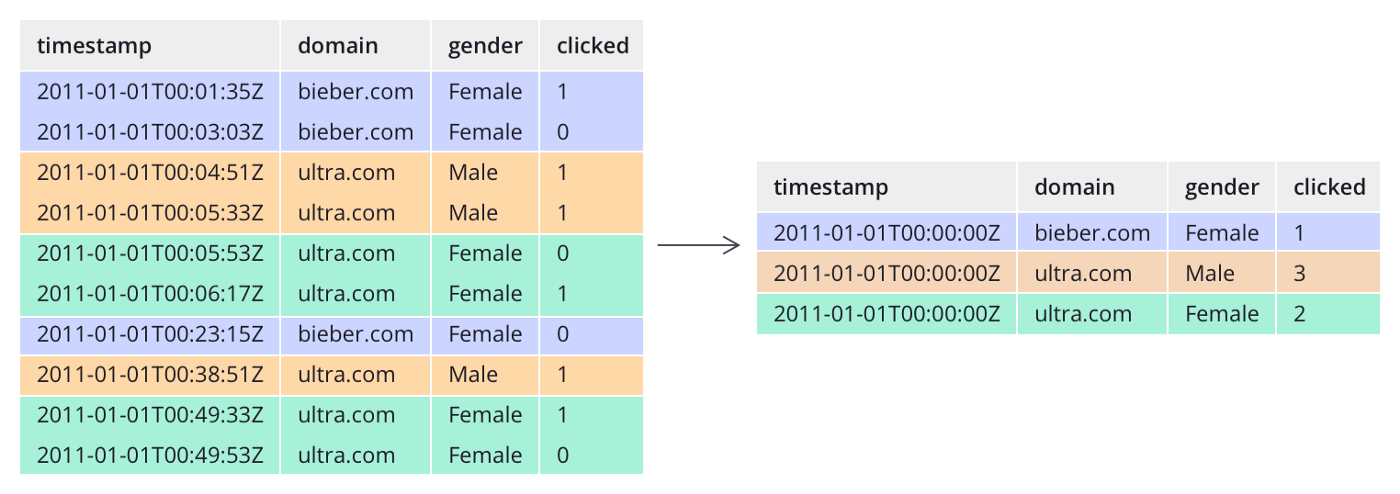
На відміну від багатьох традиційних систем, Druid може додатково попередньо агрегувати дані під час їх надходження. Цей етап попереднього агрегування відомий як зведення та може призвести до значної економії пам’яті.
Приклад агрегації даних Druid-ом:
Що далі? Далі справа за практикою. Ознайомтесь з повним описом Druid на офіційному сайті та починайте практикуватись.
Удачі! ;)
Махно Михайло.