



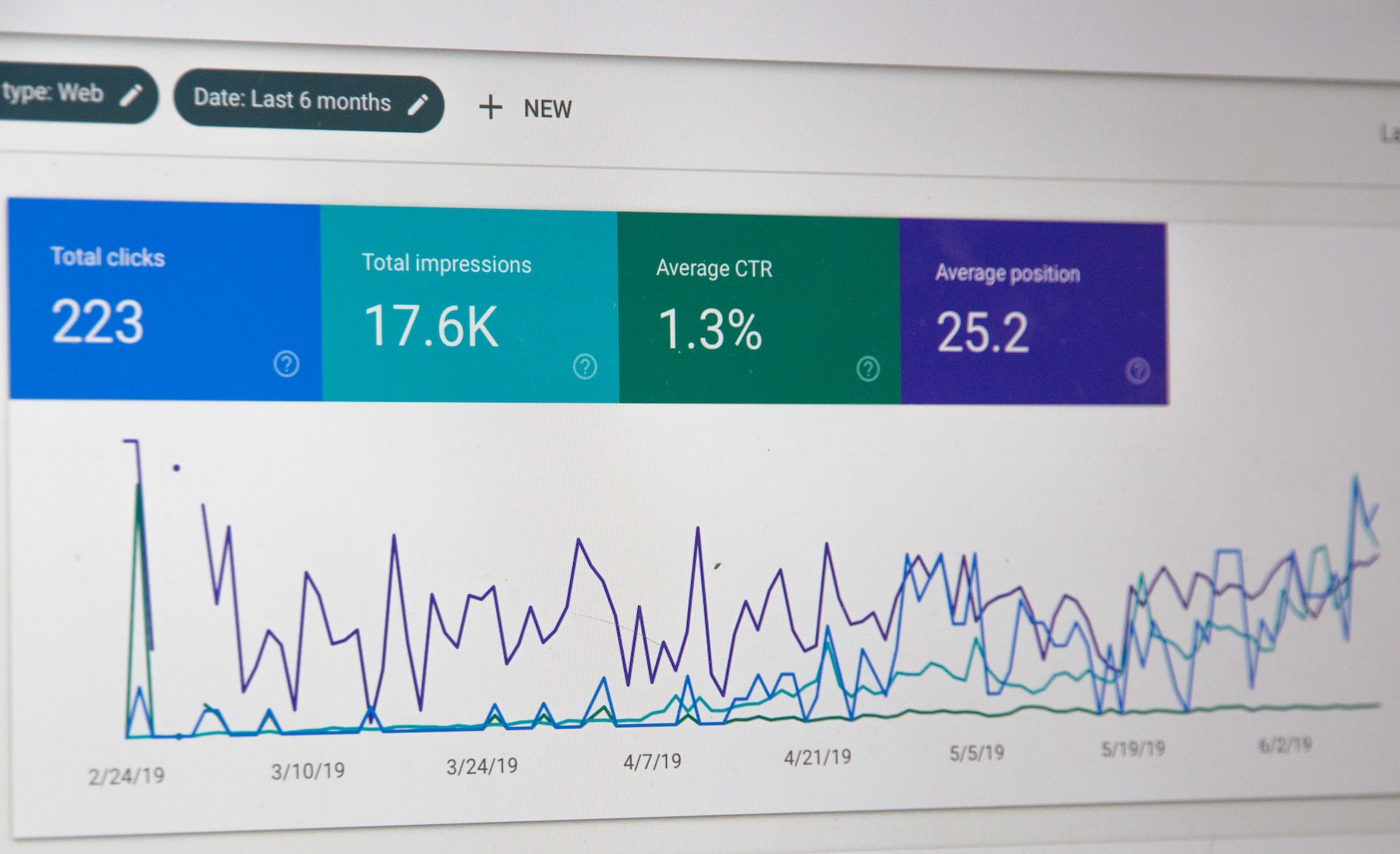
Making decisions and asking questions about the digital services you provide should be easy. However, the data you need is filtered and processed before it reaches you – often when it's too late. A triad of open-source projects – Divolte, Apache Kafka, and Apache Druid – can provide real-time data collection, streaming transmission, and interactive visualization of click streams, so you can explore what's happening on your digital channels as easily as looking out of an office window.
User behavior in digital apps is recorded as a stream of individual events, documenting every step a visitor takes from visiting a website, reading articles, clicking links, submitting forms, etc.
For many years, this data was only available to server administrators, collected as web server logs in such volume and complexity that gaining business insights was difficult. But as digital channels have grown to the critically important status they have today, so has the importance of figuring out how to use this data to quickly understand customer behavior and profiles and make effective business decisions.
Popular products like Google Analytics were created to meet this need and provide ways to make this data available to different teams in an organization. These tools store data on hosted platforms and provide a limited set of preformatted and often delayed views of user interaction.
As digital channels have spread and grown both in critical importance to the business and in the speed and volume of data, product development and market strategists need faster and more flexible access to this behavioral data, even as data sets grow to enormous scales. They need an intuitive interface that allows them to explore always fresh data in real-time, fueling their curiosity and enabling proactive decision-making.
Now, three open-source software projects allow you to maintain the flow of data from the user to the analyst or decision-maker for specialized real-time data research, bringing clickstream data under your control: where it is stored, what is stored, and how long it is stored.
Using open-source technologies to create a powerful, scalable, resilient real-time click analysis service is easier than you might expect. All components are easily accessible and continually improved thanks to the army of opensource community and organizations that also use this software. Let's look at the stack to make all this work: the stack includes Divolte, Apache Kafka, and Apache Druid. Details of each component are described below.
Divolte
Divolte can be used as the basis for creating anything from a basic web analytics dashboard to real-time recommendation engines or banner optimization systems. Using a small piece of JavaScript and a pixel in the web browsers of clients, it collects data about their behavior on the website or in the application. The Divolte tool with an Apache license was opened by GoDataDriven, which deals with key open-source projects such as Apache Airflow and Apache Flink.
The server component is Divolte Collector, which receives events from the lightweight Javascript component on the client side embedded in your website or application. Once embedded, this component will automatically collect and send details to Divolte Collector. This is a scalable and productive server for collecting click data and publishing it to a receiver, such as Kafka, HDFS, or S3.
The details included in the standard data set provide a large amount of information. Here's a sample of what's included: Device activity session, First session, IP address, etc. You can go further by adding new events and data to add richness and breadth to standard parameters. An example could be initiating a message that will be recorded when users scroll long-form pages and publish it on a real-time dashboard so that content editors can adapt their content within minutes of publication to increase ad impressions and improve the quality of their output.
Kafka
Attributes collected by Divolte can be transmitted in real-time directly into Apache Kafka with a simple configuration change.
A typical Kafka pipeline begins with receiving data from databases, message buses, APIs, and software adapters (Divolte fits here), preprocessing (normalization, filtering, transformation, and enrichment), analytics (including machine learning and pattern matching), and then consumption by reporting and process control tools, user applications, and real-time analytics.
Druid
Once events are delivered to an Apache Kafka topic, message consumers consume the events. Apache Druid is an ideal partner for using real-time data from Kafka; it allows creating dashboards and visualizations that use real-time data, truly a practical experience of data exploration for the kinds of specialized analysis needed by marketers and product developers. Using a Druid-based visualization tool, they can explore data in real time and make conclusions about what is happening now, without involving engineers.
What's next?
The rest is just practice! A good example of setting up the stack is given in this article: click!
Mykhailo Makhno


